AGENT: A Benchmark for Core Psychological Reasoning
Tianmin Shu1, Abhishek Bhandwaldar2, Chuang Gan2, Kevin A. Smith1, Shari Liu1, Dan Gutfreund2, Elizabeth Spelke3, Joshua B. Tenenbaum1, and Tomer D. Ullman3
1Massachusetts Institute of Technology
2MIT-IBM Watson AI Lab
3Harvard University
Official Benchmark on EvalAI
Abstract
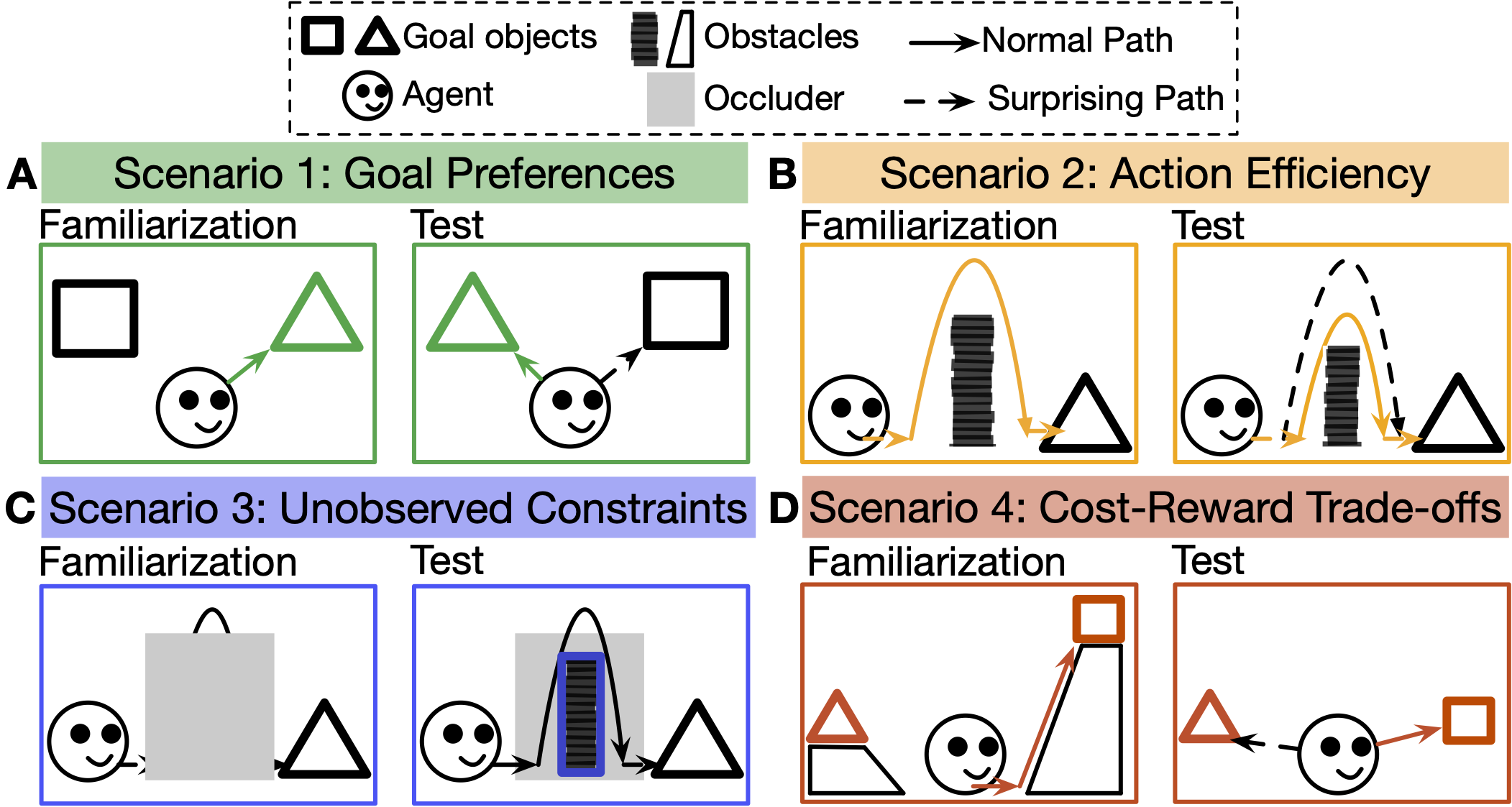
For machine agents to successfully interact with humans in real-world settings, they will need to develop an understanding of human mental life. Intuitive psychology, the ability to reason about hidden mental variables that drive observable actions, comes naturally to people: even pre-verbal infants can tell agents from objects, expecting agents to act efficiently to achieve goals given constraints. Despite recent interest in machine agents that reason about other agents, it is not clear if such agents learn or hold the core psychology principles that drive human reasoning. Inspired by cognitive development studies on intuitive psychology, we present a benchmark consisting of a large dataset of procedurally generated 3D animations, AGENT (Action, Goal, Efficiency, coNstraint, uTility), structured around four scenarios (goal preferences, action efficiency, unobserved constraints, and cost-reward trade-offs) that probe key concepts of core intuitive psychology. We validate AGENT with human-ratings, propose an evaluation protocol emphasizing generalization, and compare two strong baselines built on Bayesian inverse planning and a Theory of Mind neural network. Our results suggest that to pass the designed tests of core intuitive psychology at human levels, a model must acquire or have built-in representations of how agents plan, combining utility computations and core knowledge of objects and physics.